
Verifiable Data Doesn’t Matter until You Need Proof


Trust and tech make every distributed system functionally operate in tandem with each other. Typically, most people see the tech as the face value of a system before the financial part of things. But underneath both, trust is the invisible layer that makes these systems work. For the people who build them and the people who use them.

The internet is flooded with AI slop. LLMs are quietly but rapidly displacing what already exists. Writers, researchers, analysts, and other people assumed roles that were untouchable. But nothing gets replaced until people believe the replacement serves them better. That alone tells you everything about how much trust drives adoption.
Why would I use Claude every day if I do not trust that it will give me the answers to my questions? In the grand scheme of things, trust itself has been questioned; If a system is not fully in my control, how do I know it’s worth trusting? The question is not new; it’s the same logic that gave us blockchain validators preventing double-spending,.
But what then matters the most?
Data. It is the music you stream, the GIFs you send in chats, the employment contract you sign, the videos you watch on TikTok, the text your mom, your dad. Every format, every file, is all data. And all of it can lie.
Sometimes through negligence. Sometimes, through the simple, compounding reality that data moves through systems built by humans, stored on servers owned by big corporations, and retrieved by applications that have no obligation to show you what changed between the original and what you received.
The sharpest example here, as mentioned, is AI. Large language models (LLMs) are trained on datasets nobody can fully audit. They produce outputs nobody can fully trace. When a model confidently states a false fact, cites a paper that doesn’t exist, or generates a financial projection built on invented data, the damage can be catastrophic.
In 2023, plaintiff’s attorneys Peter LoDuca and Steven Schwartz submitted a legal brief to a US federal court written by ChatGPT during the landmark case between Mata v. Avianca, Inc. The cases were fabricated. The citations looked real. No one caught it until a judge did.
That is a data problem. To put it specifically, a verifiability problem. This is where the conversation about data stops being philosophical and starts being infrastructural because the output existed and looked correct, but there was no mechanism to prove it wasn’t.
How Walrus works:
One of the biggest problems the Sui network faced on post-mainnet was the problem of replicating data across validators. When a new validator joins the network, this validator is required to pay for storage costs in addition to the fact that these validators have to maintain the full integrity of the data that is uploaded on the Sui network.
Walrus was built to solve this problem by introducing Red Stuff encoding, a two-dimensional erasure coding system that breaks the data into fragments called slivers and distributes them across a network of storage nodes.
When a data blob is stored on the Sui blockchain, say 2GB across 50 validators, every validator stores a full copy. That redundancy creates overhead on network execution and throughput. Every new validator joining the network pays to hold the same data that every existing validator already holds, just to maintain consistency.
Through erasure coding, Walrus splits and encodes every uploaded data into slivers and adds an extra redundancy (say 10 pieces are the original slivers, 2 extra are now redundant) to these split slivers for the purpose of making sure for the whole data to be formed, only a specific number of these slivers will be needed and not the entire sliver and their redundancies. Solving storage overhead is only half the problem.
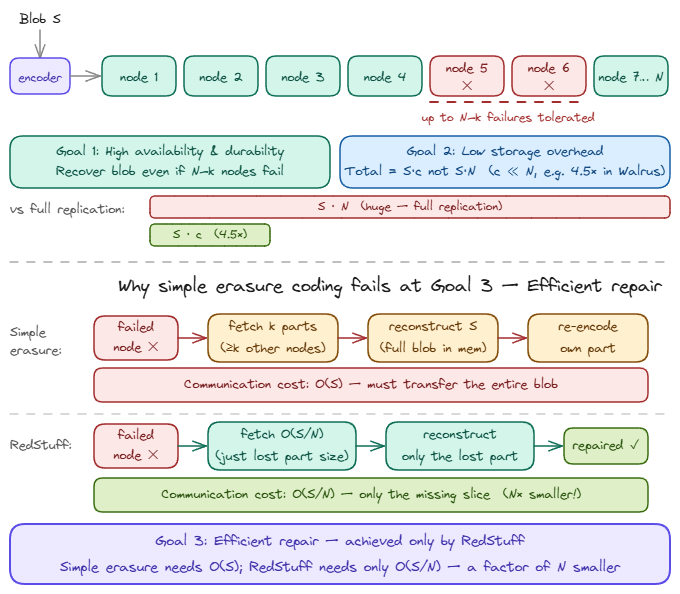
Unfortunately, and upon retrieval, some nodes may go offline and fail to present their sliver. If enough slivers are missing, the full blob cannot be reconstructed. RedStuff handles this. When slivers are missing, nodes communicate with each other, locate enough remaining slivers, and mathematically reconstruct the missing pieces. The system doesn’t need every sliver, just enough of them. This is Byzantine fault tolerance in practice: Walrus remains fully functional even when up to one-third of storage nodes are offline or uncooperative.
What happens next? Each storage node that receives its sliver verifies it against the blob ID, a metadata derived from the stored content. A change in a single byte of this original file changes the blob ID completely.
The node then checks that a valid blob resource authorizes the store. If everything checks out, it signs a statement to confirm it holds the silver. These signatures are collected across the network and combined into a single availability certificate. An on-chain record on Sui that anyone can reference.
This is the Proof of Availability. This is what separates Walrus from every prior attempt at decentralized storage. Filecoin and Arweave store data, but Walrus stores data and proves it. The certificate lives on-chain, it is readable by anyone, and queryable by smart contracts.
Use cases: Where Verifiable Data Matters
1. Ad Fraud and Verifiable Impressions
The internet has largely introduced the commodification of things, where content and social media merge. We’ve seen this on OnlyFans, Twitch, YouTube Live events, and others that make digital advertising easier.
In digital advertising, the trust problem is almost laughably old. Advertisers spend billions paying for eyeballs that never existed, bots, ghost traffic, pixel stuffing.
If you cannot prove that an impression happened, when it happened, and whether the creative was actually served intact, you have no case.
Walrus becomes relevant here because the audit trails of every bid, impression log, and creative server can be stored as verifiable blobs. The strongest product to emerge from this vertical is AlkimiExchange
2. Institutional Data Archival
Just as @0xngmi highlights here; institutional adoption is rising exponentially, but these institutions do not just want data; they need it to be auditable, retrievable, and intact across time.
We’ve seen this expand down to Blockworks, trying to create a metric for investor relations. Most on-chain data infrastructure is built for speed, not permanence. Data gets trimmed, nodes churn, and records quietly disappear.
Walrus changes this. Blobs stored on Walrus carry redundancy guarantees and Byzantine fault tolerance. This means datasets survive node failures by design, not by luck. This is exactly the infrastructure that institutional-grade archival demands. It’s what makes Walrus the credible storage layer behind what Allium is building.
3. AI Model Weights and Training Data
If you train a model on data, you cannot prove that you are exposed legally, reputationally, and structurally. Model weights are large, training datasets are larger, and the current infrastructure for proving that “this model was trained on this data at this point” is almost nonexistent.
This is just one part of the data provenance problem. AI model weights and training data core problems include:
Errors in reasoning.
Outdated information.
Bias caused by previous prompts.
As this continues, it’s no longer going to be a problem of “which AI model is the best?” but “how can the output of these models be verified?”.
Walrus handles unstructured data blobs efficiently enough that weights and datasets can be stored with an integrity guarantee and if this is paired with zero-knowledge proofs, the very trust primitive described earlier, and you now have a system where a node can prove it holds certain training data without exposing the data itself. Provenance becomes computable.
4. Fraud Proofs and Data Availability
Rollups batch hundreds or thousands of transactions off the main chain, execute them in a compressed environment, and then post a summary back to Layer 1.
For instance, Optimistic rollups assume the posted state is valid unless someone challenges it. That challenge mechanism is called fraud proof. If a sequencer posts a fraudulent state transition, any honest participant can raise a dispute and prove the sequencer lied. The dispute resolution, however, requires access to the original transaction data. You cannot prove fraud without the receipts.

What happens when the data needed to construct a fraud-proof simply is not there?
Walrus addresses this directly. Blobs posted by rollup sequencers are stored with erasure coding, meaning the data is split into redundant slivers distributed across the network, and the full dataset is reconstructable from only a subset of those slivers.
RedStuff handles the case where some nodes are offline or uncooperative, communicate with each other, gather enough slivers, and reconstruct what is missing. Byzantine fault tolerance means the system holds even with up to a third of storage nodes failing.
Finishing Thoughts
For most of human history, trust was a social technology. You trusted your bank because the government backed it.
You trusted the news because an institution published it. You trusted the document because an official stamped it. Even when the stamp was never proof, but a theatre. The entire architecture of institutional trust was built not on verification, but on the assumption that verification was too expensive, too slow, too complicated for ordinary people to do themselves. So we delegated it. And in delegating it, we handed over something we didn’t fully notice we were losing.
Walrus makes that delegation optional. With a certificate, an on-chain record that shows you the data exists, and in what form, open to anyone who wants to look.
 | A guest post by
|